Hadoop基础
Hadoop
Hadoop主要分为三大模块,分别是 HDFS(文件分布系统), MapReduce(分布式计算框架),YARN(资源调度管理)。
HDFS
HDFS的组成
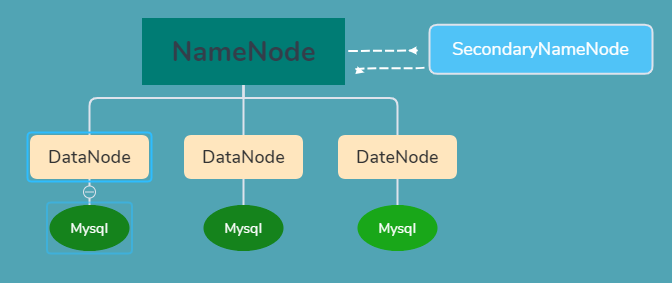
NameNode
主要作用
- 存储数据
存储对应的元数据,其中元数据包括:目录结构树,文件,数据块和副本的映射关系(不是数据信息,是映射关系)
- 存储位置
内存和磁盘
包含的文件
fsimage:元数据镜像文件,存储某一时段NameNode内存元数据信息即保存了最新的元数- 据checkpoint。edits:操作日志文件。fstime:保存最近一次checkpoint的时间。
1、NameNode 为了保证交互速度,会在内存中保存这些元数据信息,但同时也会将这些信息保存到硬盘上进行持久化存储;
2、fsimage文件是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,不能直接修改。
3、Hadoop在重启时就是通过fsimage+edits来状态恢复,fsimage相当于一个checkpoint,首先将最新的checkpoint的元数据信息从fsimage中加载到内存,然后逐一执行edits修改日志文件中的操作以恢复到重启之前的最终状态。
4、Hadoop的持久化过程是将上一次checkpoint以后最近一段时间的操作保存到修改日志文件edits中。
SecondaryNameNode
- 主要作用
作为NameNode的冷备份;合并fsimage(元数据镜像文件(文件系统的目录树))和fsedits然后再发给Namenode,分担NameNode的一部分工作。
1、edits:元数据的操作日志(针对文件系统做的修改操作记录)
2、Namenode内存中存储的是fsimage+edits。
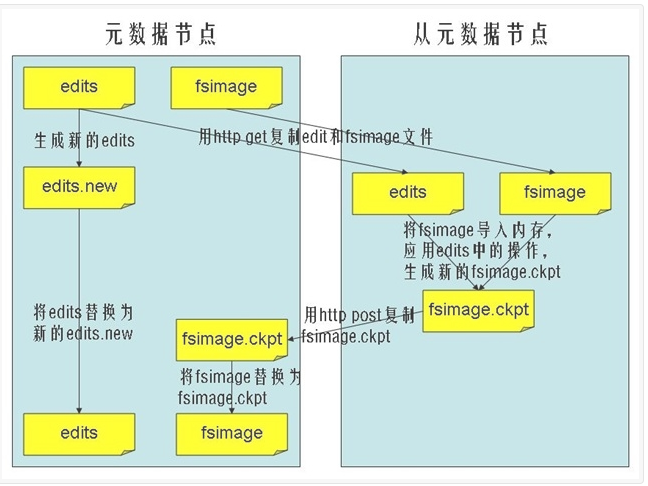
SecondaryNameNode节点 的主要功能是周期性将元数据节点的命名空间镜像文件(fsimage)和修改日志(edits)进行合并,以防edits日志文件过大。下面来看一看合并的流程:
1、SecondaryNameNode节点 需要合并时,首先通知NameNode节点生成新的日志文件,以后的日志都写到新的日志文件中。
2、SecondaryNameNode节点 用http get从NameNode节点获得fsimage文件及旧的edits日志文件。
3、SecondaryNameNode节点 将 fsimage 文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
4、SecondaryNameNode节点将新的fsimage文件用http post传回NameNode节点上。
5、NameNode 节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
6、这样NameNode 节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
- 注意:
1、这种机制有个问题:因edits存放在NameNode中,当NameNode挂掉,edits也会丢失,导致利用Secondary NameNode恢复Namenode时,会有部分数据丢失。
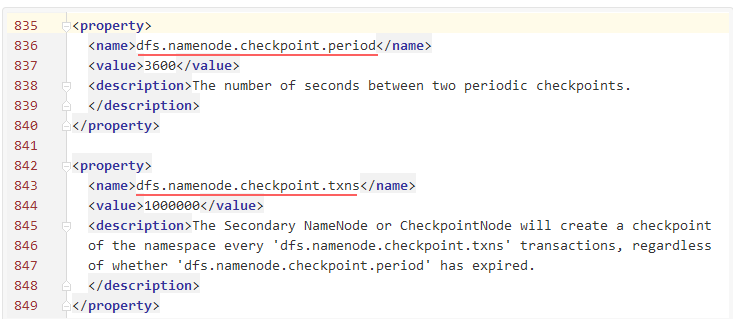
2、HDFS设置了两种机制进行条件合并(hdfs-site.xml):
第一种:当时间间隔大于或者等于dfs.namenode.checkpoint.period配置的时间是做合并(默认一小时)。
第二种:当最后一次往journalNode写入的TxId(这个可以在Namenode日志或者50070界面可以看到)和最近一次做checkpoint的TxId的差值大于或者等于dfs.namenode.checkpoint.txns配置的数量(默认1000000)时做一次合并。
引用的博客:参考资料
DataNode
- 主要作用
主要负责存储对应的文件(这里的文件是对应的数据块,Hadoop2.x以后默认大小为128M),备份对应的文件(副本数目可在配置里设置dfs.replication)。
HDFS的优点和缺点
HDFS优点
1、可构建在廉价机器上。
2、高容错性。
3、适合批处理。
4、适合大数据处理。
5、流式文件访问。
HDFS缺点
1、低延迟数据访问。
2、小文件存取。
3、并发写入、文件随机修改。
*HDFS文件系统为什么不适用于存储小文件? *
这和HDFS系统底层设计实现有关系的,HDFS本身的设计就是用来解决海量大文件数据的存储。当数据被HDFS存储的时候,它会被切割成多个的独立的数据块,而这些数据块的信息会被存储在元数据中。如果文件越小,对应的元数据里内存空间就会被占用,从而造成性能上的浪费。
如何解决?
- 1、采用
HAR的归档方式。
HAR为构建在其它文件系统上用于文件存档的文件系统,通常将hdfs中的多个文件打包成一个存档文件,减少Namenode内存的使用,可以直接使用hadoop archive命令创建HAR文件。创建HAR的过程是在运行一个mr作业。
HAR在对小文件进行存档后,原文件不会被删除,且创建之后不能改变,文件名中也不能有空格存在,否则会报异常
- 2、采用
CombineFileInputFormat。
CombineFileInputFormat是一种新的inputformat,用于将多个文件合成一个单独的split,而且它还可以考虑数据的存储位置。
- 3、开启
JVM重用。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在hadoop的mapred-site.xml文件中进行配置,通常在10-20之间。如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
HDFS的其它功能
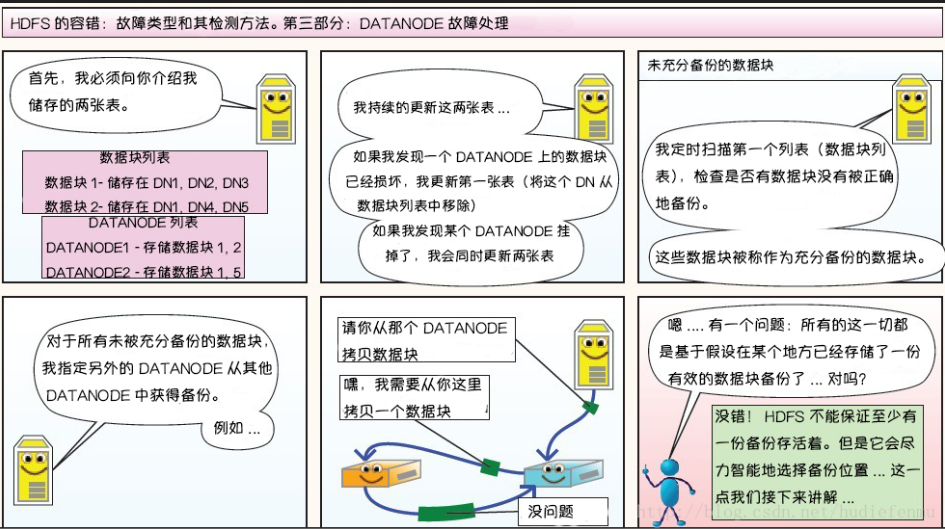
心跳机制和重新复制
每个DataNode 定期向 NameNode 发送心跳消息,(DataNode向NameNode汇报的信息有2点,一个是自身DataNode的状态信息,另一个是自身DataNode所持有的所有的数据块的信息。)如果超过指定时间没有收到心跳消息,则将DataNode 标记为死亡。NameNode 不会将任何新的IO 请求转发给标记为死亡的DataNode,也不会再使用这些 DataNode 上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode 会跟踪这些块,并在必要的时候进行重新复制。
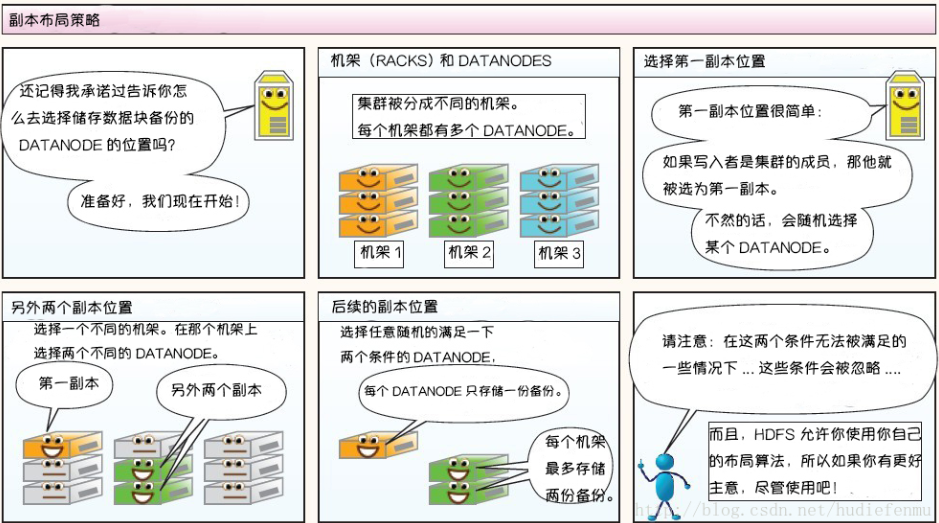
副本放置策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
HDFS的读写流程
HDFS的写操作
说明:以下内容引入:Hadoop-HDFS之读写流程
准备工作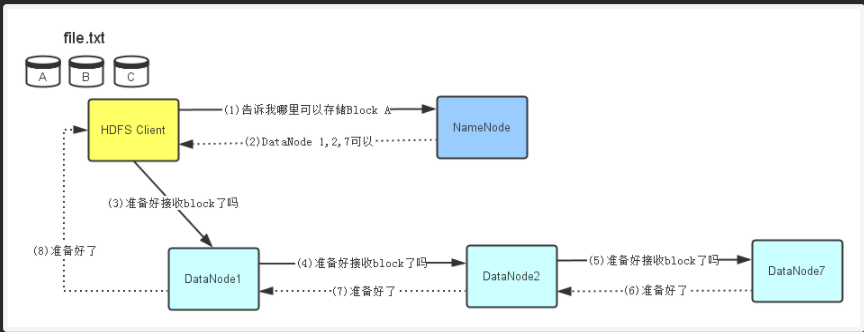
1、HDFS client先会去询问NameNode,看哪些DataNode可以存储文件。文件的拆分是在HDFS client中完成的,比如拆分成A、B、C。
2、NameNode查看它的元数据信息,发现DataNode 1,2,7上有空间可以存储Block A,于是将此信息告诉HDFS Client。
3、HDFS Client接到NameNode返回的DataNode列表信息后,它会直接联系第一个DataNode1,让它准备好接收Block A(建立TCP连接)。
4、在DataNode1建立好TCP连接后它会把HDFS Client要写Block A的请求顺序传给DataNode2(在与HDFS Client建立好TCP连接后从HDFS Client获得的DataNodel1信息),同理传递给DataNode7。
5、当DataNode7准备好后,会回传信息过来,HDFS Client接到信息后表示都准备好了,就可以写数据了。
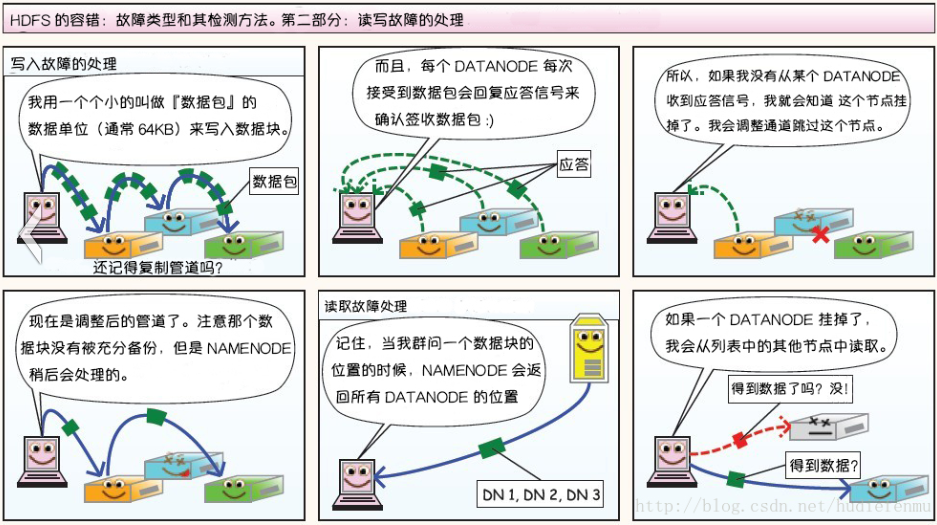
写入数据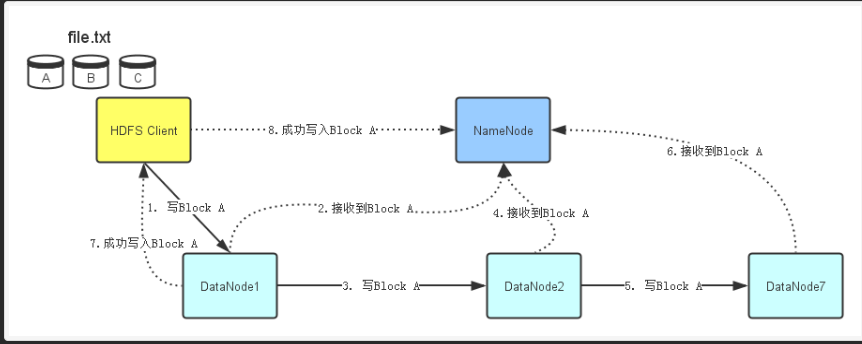
1、HDFS Client开始往DataNode1写入Block A数据。同准备工作一样,当DataNode1接收完Block A数据后,它会顺序将Block A数据传输给ataNode2,然后DataNode2再传输给DataNode7。
2、每个DataNode在接收完Block A数据后,会发消息给NameNode,告诉它Block数据已经接收完毕。
3、NameNode同时会根据它接收到的消息更新它保存的文件系统元数据信息。
4、当Block A成功写入3个DataNode之后,DataNode1会发送一个成功信息给HDFS Client,同时HDFS Client也会发一个Block A成功写入的信息给NameNode。之后,HDFS Client才能开始继续处理下一个Block-Block B。
HDFS读数据操作
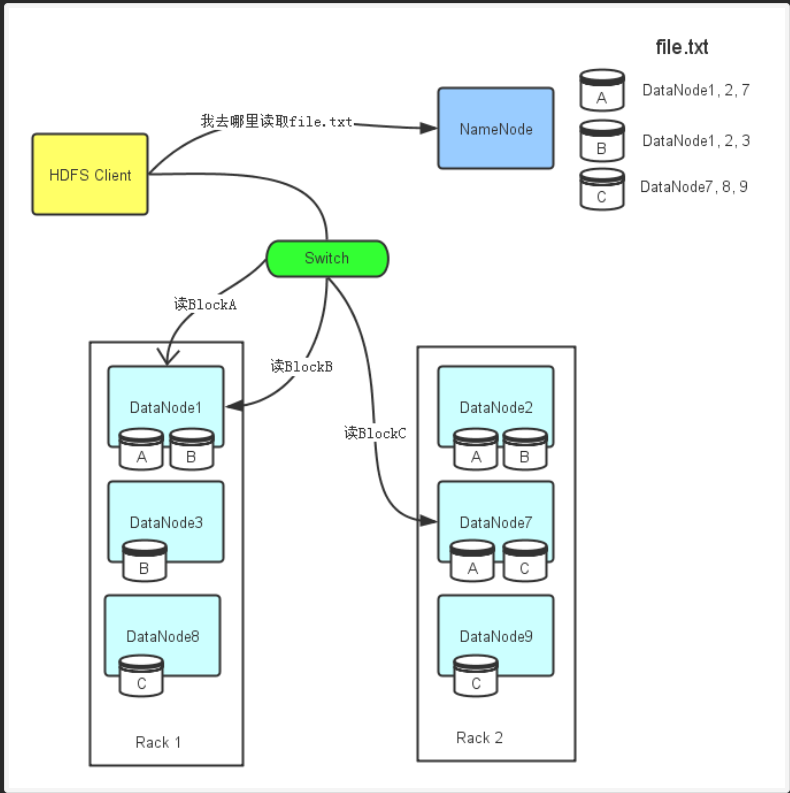
1、HDFS Client会先去联系NameNode,询问file.txt总共分为几个Block而且这些Block分别存放在哪些DataNode上。
2、由于每个Block都会存在几个副本,所以NameNode会把file.txt文件组成的Block所对应的所有DataNode列表都返回给HDFS Client。
3、然后HDFS Client会选择DataNode列表里的第一个DataNode去读取对应的Block。比如由于Block A存储在DataNode1,2,7,那么HDFS Client会到DataNode1去读取Block A;Block C存储在DataNode7,8,9,那么HDFS Client就回到DataNode7去读取Block C。
补充
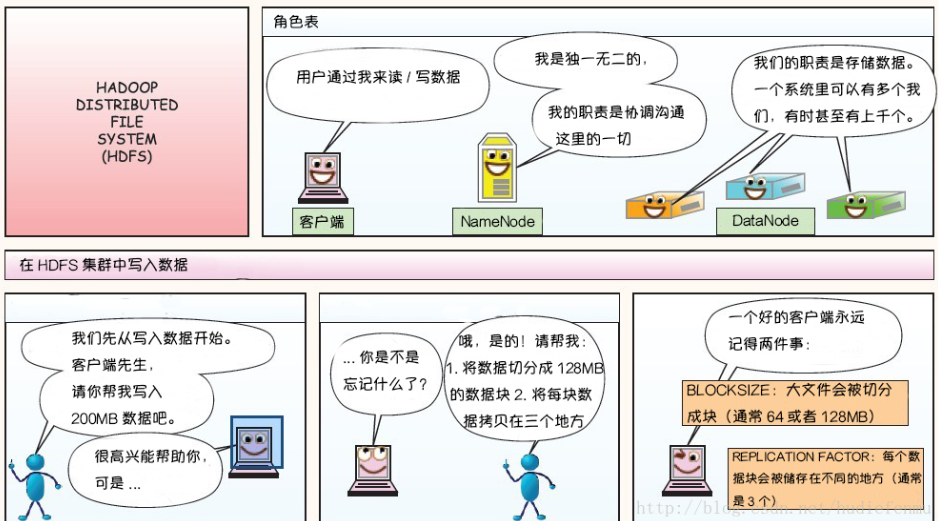
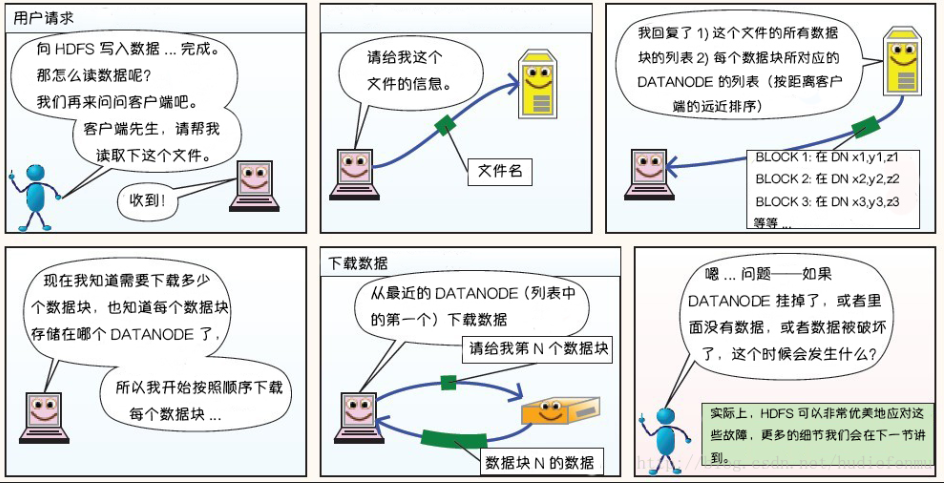
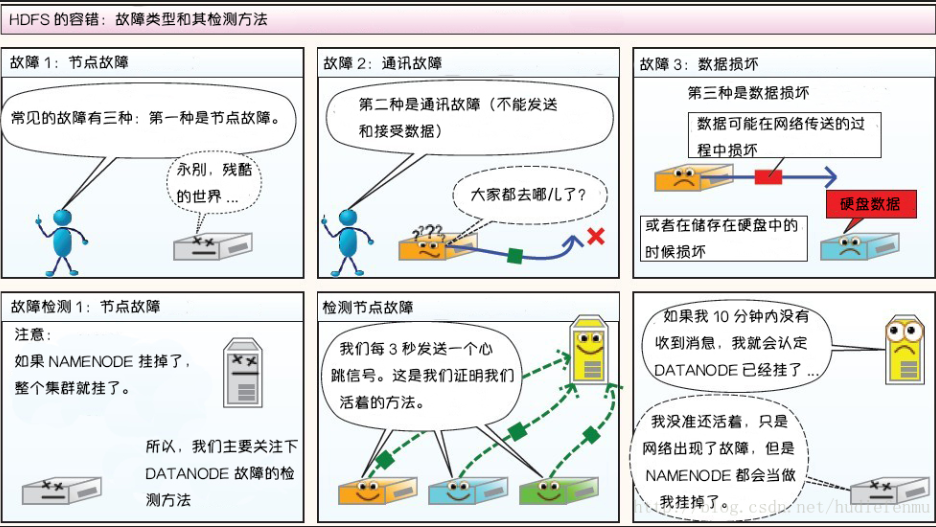
漫画详解HDFS的存储原理
说明:以下图片引用自博客:翻译经典 HDFS 原理讲解漫画
HDFS写数据原理
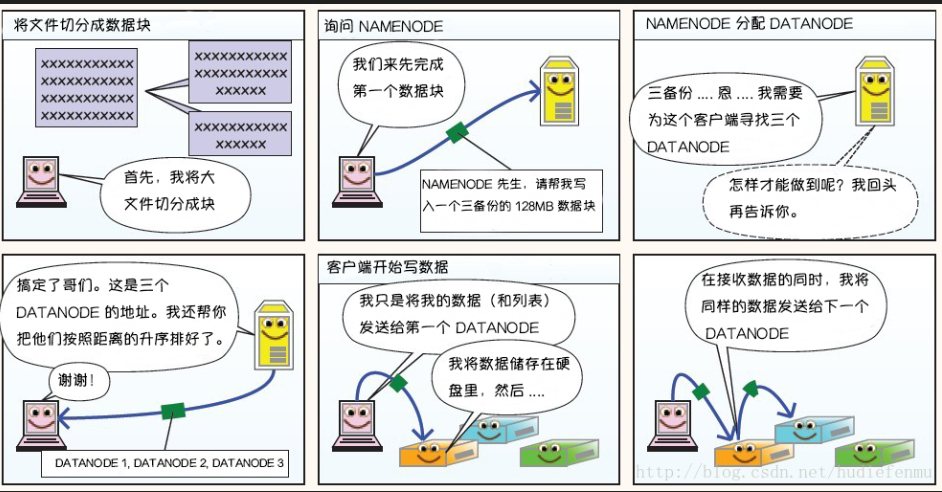
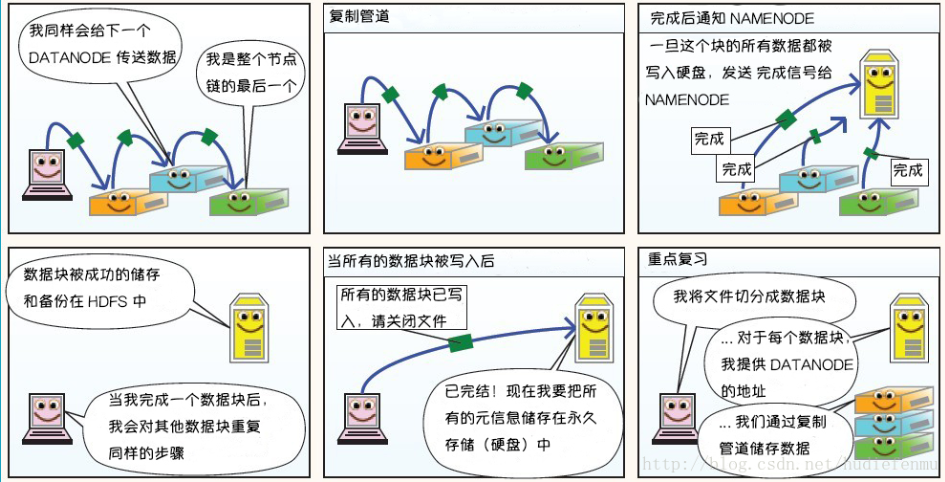
HDFS读数据原理
HDFS故障类型和其检测方法
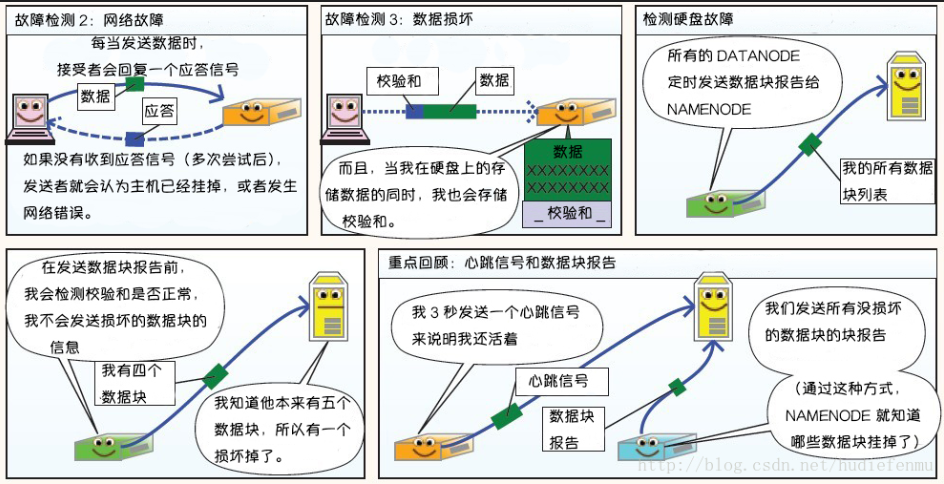
读写故障的处理
DataNode 故障处理
副本布局策略