Flume_基础
Flume的定义
Flume 是一个分布式的、高可靠的、高可用的将大批量的不同数据源的日志数据收集、聚合、移动到数据中心(HDFS)进行存储的系统。即是日志采集和汇总的工具。
Flume的优势
- 可以高速采集数据,采集的数据能够以想要的文件格式及压缩方式存储在
HDFS上。 - 事务功能保证了数据在采集的过程中数据不丢失。
- 部分
Source保证了Flume挂了以后重启依旧能够继续在上一次采集点采集数据,真正做到数据零丢失。
Flume的组成
Source(源端数据采集):Flume提供了各种各样的Source、同时还提供了自定义的Source。Channel(临时存储聚合数据):主要用的是Memory Channel和File Channel(生产最常用),生产中Channel的数据一定是要监控的,防止Sink挂了,撑爆Channel。Sink(移动数据到目标端):如HDFS、KAFKA、DB以及自定义的Sink。
Flume的架构
- 单
Agent:
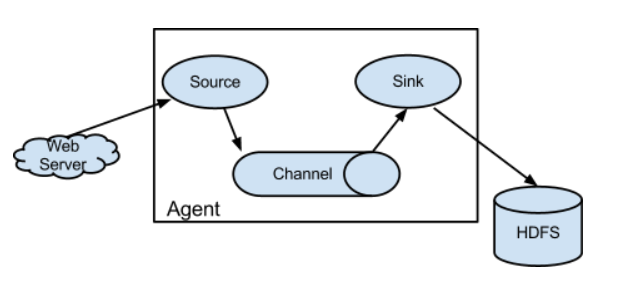
- 串联
Agent:
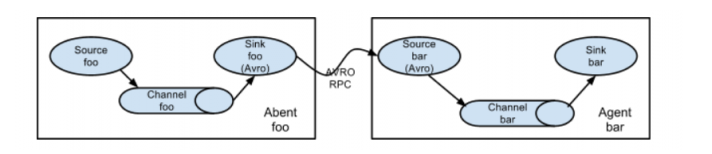
- 并联
Agent:
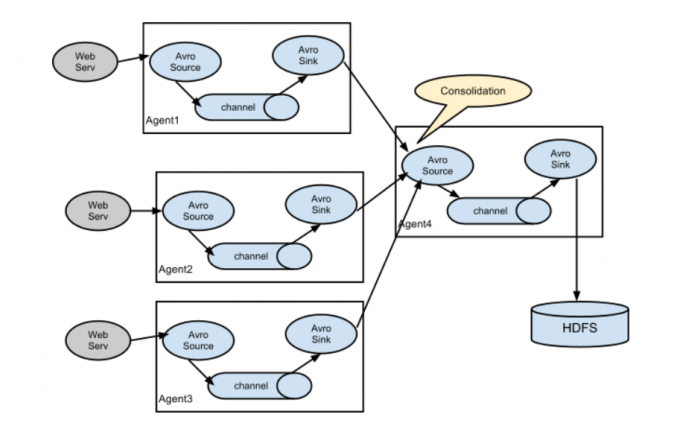
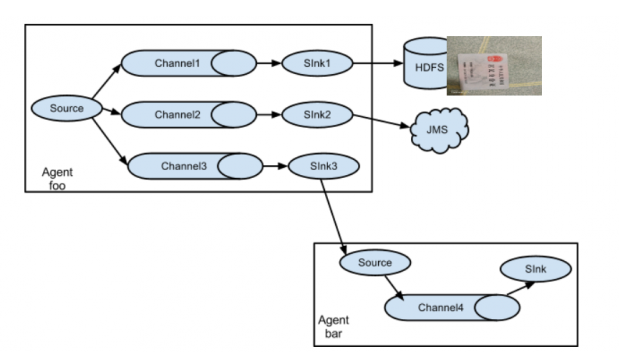
- 多
SinkAgent:
Agent配置使用案列
Flume的使用其实就是Source、Channel、Sink的配置。Agent=Source+Channel+Sink,其实Agent就是Flume的配置文件。- 一个配置文件可以配置多个
Agent的。 Event:Flume数据传输的最小单位,一个Event就是一条记录,由Head和Body两个部分组成,Head存储的是管道,Body存储的是字节数组。
使用Exec Source采集文件数据到HDFS
- 缺点:
- 虽然此种
Tail方式可以将日志数据采集到HDFS,但是Tail -F进程挂了咋办,还是会丢数据!生产上是行不通的。无法做到高可用。 - 其次上面的采集流程并未解决生成大量小文件的问题,无法做到高可靠。
Tail只能监控一个文件,生产中更多的是监控一个文件夹。不能满足需求。
使用Spooling Directory Source采集文件夹数据到 HDFS
- 写到
HDFS上的文件大小最好是100M左右,比Blocksize的值(128M)略低。 - 一般使用
Rolllnterval(时间)、RollSize(大小)来控制文件的生成,哪个先触发就会生成HDFS文件,将根据条数的Roll关闭。 RollSize控制的大小是指的压缩前的,所以若HDFS文件使用了压缩,需调大Rollsize的大小。- 当文件夹下的某个文件被采集到
HDFS上,会有个Complete的标志。 - 使用
Spooling Directory Source采集文件数据时若该文件数据已经被采集,再对该文件做修改是会报错的停止的,其次若放进去一个已经完成采集的同名数据文件也是会报错停止的。 - 写
HDFS数据可按照时间分区,注意改时间刻度内无数据则不会生成该时间文件夹。 - 生成的文件名称默认是前缀+时间戳,这个是可以更改的。
- 缺点
- 虽然能监控一个文件夹,但是无法监控递归的文件夹中的数据。
- 若采集时
Flume挂了,无法保证重启时还从之前文件读取的那一行继续采集数据。
使用Taildir Source采集文件夹数据到HDFS
Taildir Source是Apache flume1.7新推出的,但是CDH Flume1.6做了集成。Taildir Source是高可靠(Reliable)的Source,他会实时的将文件偏移量写到Json文件中并保存到磁盘。下次重启Flume时会读取Json文件获取文件偏移量,然后从之前的位置读取数据,保证数据零丢失。Taildir Source可同时监控多个文件夹以及文件。即使文件在实时写入数据。Taildir Source也是无法采集递归文件下的数据,这需要改造源码。Taildir Source监控一个文件夹下的所有文件一定要用.*正则。

