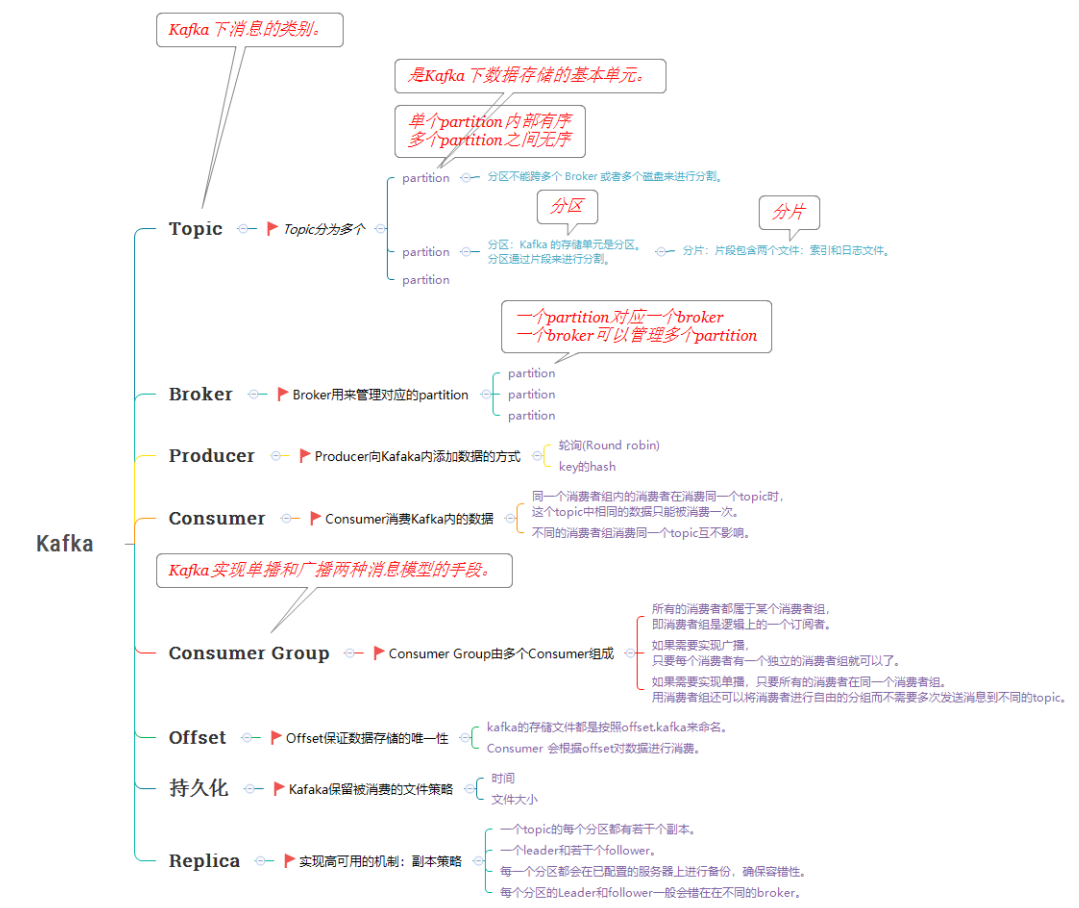
Kafka_架构
Topic可以类比为数据库中的库。Partition可以类比为数据库中的表。- 一个
Topic就是一个消息队列,然后它把每个Topic又分为很多个Partition。 - 一个
Topic可以有多个消费者组。 - 同一个消费者组内的消费者在消费同一个
Topic时,这个Topic中相同的数据只能被消费一次,即每个Partion只会把消息发给该消费者组中的一个消费者。 - 不同的消费者组消费同一个
Topic互不影响。 - 一台Kafka服务器节点就是一个
Broker。一个集群由多个Broker组成。一个Broker可以容纳多个Topic。
Topic
Topic 就是数据主题,Kafka 建议根据业务系统将不同的数据存放在不同的 Topic 中。
Kafka中的Topics总是多订阅者模式,一个Topic可以拥有一个或者多个消费者来订阅它的数据。- 一个大的
Topic可以分布式存储在多个Kafka Broker中。 Topic可以类比为数据库中的库。- 一个
Topic就是一个消息队列,然后它把每个Topic又分为很多个Partition。 - 在每个
Partition内部消息强有序,相当于有序的队列,其中每个消息都有个序号Offset,比如 0 到 12,从前面读往后面写。
Partition
- 一个
Topic可以分为多个Partition,通过分区的设计,Topic可以不断进行扩展。一个Topic的多个分区分布式存储在多个Broker(服务器)上。此外通过分区还可以让一个Topic被多个Consumer进行消费。以达到并行处理。分区可以类比为数据库中的表。 Partition内部有序,但一个Topic的整体(多个Partition间)不一定有序Kafka只保证按一个Partition中的顺序将消息发给Consumer,Partition中的每条消息都会被分配一个有序的Id(Offset),每个Partition内部消息是一个强有序的队列,但不保证一个Topic的整体(多个Partition间)的顺序。- 一个
Partition对应一个Broker,一个Broker可以管理多个Partition。 Partition可以很简单想象为一个文件,Partition对应磁盘上的目录,当数据发过来的时候它就往这个Partition上面追加,消息不经过内存缓冲,直接写入文件。
Kafka 为每个主题维护了分布式的分区(Partition)日志文件,每个 Partition 在 Kafka 存储层面是 Append Log 。任何发布到此partition的消息都会被追加到 Log 文件的尾部,在分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,也就是我们的 Offset 。Offset 是一个 long 型的数字,我们通过这个 Offset 可以确定一条在该 Partition 下的唯一消息。在 Partition下面是保证了有序性,但是在 Topic 下面没有保证有序性。
- 每个
Partition都会有副本,可以在创建Topic时来指定有几个副本。
Offset
Kafka的存储文件都是按照Offset。Kafka来命名,用Offset做名字的好处是方便查找。- 数据会按照时间顺序被不断第追加到分区的一个结构化的
Commit Log中!每个分区中存储的记录都是有序的,且顺序不可变! - 这个顺序是通过一个称之为
Offset的Id来唯一标识!因此也可以认为Offset是有序且不可变的! - 在每一个消费者端,会唯一保存的元数据是
Offset(偏移量),即消费在Log中的位置,偏移量由消费者所控制。通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从”现在”开始消费。
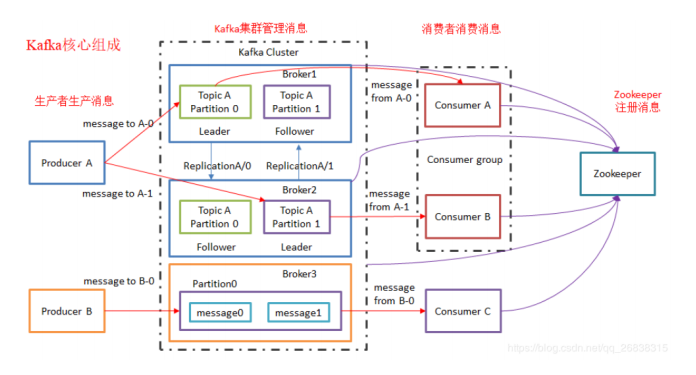
Topic拓扑结构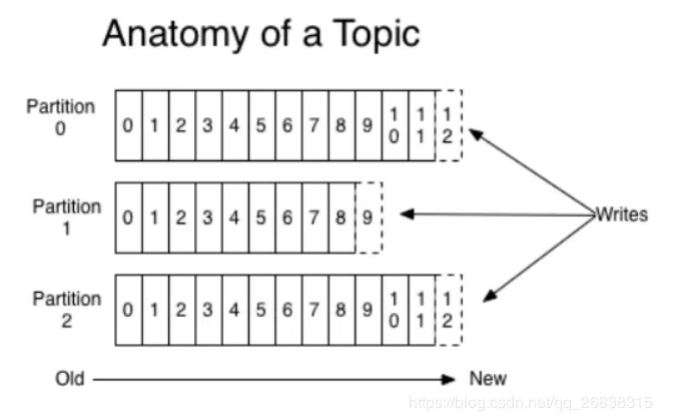
数据流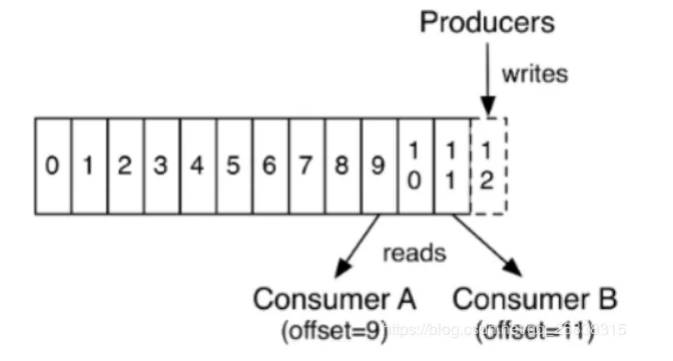
Producer
消息生产者,就是向 Kafka Broker 发消息的客户端。将记录分配到 Topic 的指定 Partition(分区)中。
两种发送的机制:
- 轮询(
Round Robin)
先随机到某一个Partition 上一直持续的写,大概写个十分钟,再随机到一个 Partition 再去写,所以一般建议生产消息都按照建个 Key来按照 Hash 去分,还可以自定义按照 Key怎么去分。
Key的Hash
如果 Key 为 NULL,就是轮询,否则就是按照 Key 的 Hash。
Consumer
消息消费者,向 Kafka Broker取消息的客户端。
- 每个
Consumer都有自己的消费者组Group。 - 同一个消费者组内的消费者在消费同一个
Topic时,这个Topic中相同的数据只能被消费一次。 - 不同的消费者组消费同一个
Topic互不影响。 - 低版本0.9之前将
Offset保存在Zookeeper中,0.9及之后保存在Kafka的“__consumer_offsets”主题中。
Consumer Group
每个消费者都会使用一个消费组名称来进行标识。同一个组中的不同的消费者实例,可以分布在多个进程或多个机器上。
- 一个
Topic可以有多个消费者组。Topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个Partion只会把消息发给该CG中的一个Consumer。 - 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;
- 消费者组之间互不影响。
- 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者
- 实例(单播)。即每个消费者可以同时读取一个
Topic的不同分区!
消费者组是 Kafka 用来实现一个 Topic 消息的广播(发给所有的消费者)和单播(发给任意一个消费者)的手段。
- 如果需要实现广播,只要每个消费者有一个独立的消费者组就可以了。
- 如果需要实现单播,只要所有的消费者在同一个消费者组。用消费者组还可以将消费者进行自由的分组而不需要多次发送消息到不同的
Topic。
Broker
Kafka 集群的 Server,一台 Kafka服务器节点就是一个 Broker ,负责处理消息读、写请求,存储消息,在 Kafka Cluster 这一层这里,其实里面是有很多个 Broker 。
- 一个集群由多个
Broker组成。一个Broker可以容纳多个Topic。 Broker是组成Kafka集群的节点,Broker之间没有主从关系,各个Broker之间的协调依赖于。Zookeeper,如数据在哪个节点上之类的。Kafka集群中有一个Broker会被选举为Controller,负责管理集群Broker的上下线,所有Topic的分区副本分配和Leader选举等工作。Controller的管理工作都是依赖于Zookeeper的。
Replica副本机制
副本,为保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作, Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- 日志的分区
Partition(分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性。 - 每个分区都有一台
Server作为 “Leader”,零台或者多台Server作为Follwers。Leader Server处理一切对Partition(分区)的读写请求,而Follwers只需被动的同步Leader上的数据。当Leader宕机了,Followers中的一台服务器会自动成为新的Leader。通过这种机制,既可以保证数据有多个副本,也实现了一个高可用的机制! - 同一个
Partition可能会有多个Replication(对应server.properties配置中的default.replication.factor=N)。没有Replication的情况下,一旦Broker宕机,其上所有Partition的数据都不可被消费,同时Producer也不能再将数据存于其上的Patition。引入Replication之后,同一个Partition可能会有多个Replication,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replication作为Follower从Leader中复制数据。 - 基于安全考虑,每个分区的
Leader和Follower一般会错在在不同的Broker!

